OCRソフトPDNobを無料ダウンロード:https://bit.ly/4tuvz7c
スキャンしたPDFをExcel(.xlsx)形式に変換したいと考えたことはありませんか?
スキャンPDFは画像として保存されているため、コピー&ペーストでは文字や表データを正確に取得できません。特に請求書や帳票、一覧表などは、手作業での入力が必要になり、大きな手間がかかります。
こうした問題を解決するのが OCR(光学文字認識) です。
今回、OCRを使ってスキャンしたPDFをエクセルに変換する方法を、日本語対応・精度の観点からわかりやすく解説します。
Part1. OCRとは?
OCR(Optical Character Recognition/光学文字認識)とは、画像やスキャンされたPDF内の文字を認識し、編集・検索できるテキストデータに変換する技術のことです。
スキャンPDFは一見すると通常の文書に見えますが、実際には文字が画像として保存されています。そのため、直接編集や検索はできません。
OCRを使用することで、文字・数字・表の構造を読み取り、WordやExcelで編集できる状態に変換できます。
たとえば、次のようなファイルは、そのままでは文字編集ができません。
- 画像として保存されたPDF
- スキャンした書類
- NotebookLMから書き出した「画像型PDFスライド」
こうしたファイルにOCRを実行すると、
文字情報が自動で抽出され、コピー・編集・検索が可能なPDFになります。
Part2. スキャンPDFをエクセルに変換するメリット
データを「計算・集計」できるようになる
スキャンPDFのままでは数値計算や並び替えができませんが、Excelに変換すれば、関数やフィルターを使った集計・分析が可能になります。
修正・再利用が簡単
Excel形式なら、数値修正や項目追加もスムーズです。定期的に更新する資料や、社内共有用のデータ管理にも向いています。
業務効率が大幅に向上
OCRで自動変換すれば、手入力に比べて作業時間とミスを大きく減らせます。
Part3. OCRでスキャンしたPDFをExcelに変換する方法
方法1:PDNob PDF編集ソフトを使う(おすすめ)
日本語の認識精度や、表の行・列構造をできるだけ崩さずにExcelへ変換したい場合は、OCR機能を搭載した PDNob PDF編集ソフトを使う方法が効率的です。
スキャンPDFをそのまま読み込み、OCR処理後にExcel(.xlsx)形式として出力できるため、手作業での修正を最小限に抑えられます。
変換手順
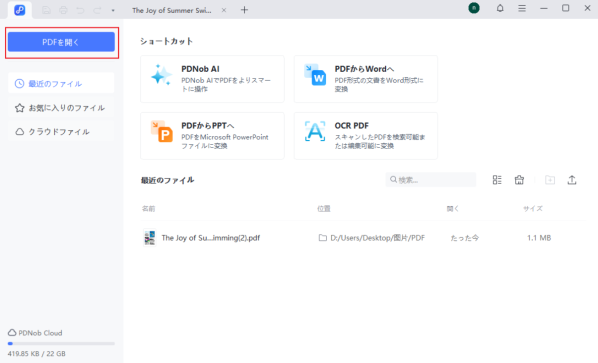
ステップ1.PDNobを起動して、スキャンPDFを読み込む
公式サイトからPDNobをインストールし、ソフトを起動します。
画面の「PDFを開く」をクリックし、エクセルに変換したいスキャンPDFファイルを選択します。
OCRソフトPDNobを無料ダウンロード:https://bit.ly/4tuvz7c
スキャンしたPDFをExcel(.xlsx)形式に変換したいと考えたことはありませんか?
スキャンPDFは画像として保存されているため、コピー&ペーストでは文字や表データを正確に取得できません。特に請求書や帳票、一覧表などは、手作業での入力が必要になり、大きな手間がかかります。
こうした問題を解決するのが OCR(光学文字認識) です。
今回、OCRを使ってスキャンしたPDFをエクセルに変換する方法を、日本語対応・精度の観点からわかりやすく解説します。
Part1. OCRとは?
OCR(Optical Character Recognition/光学文字認識)とは、画像やスキャンされたPDF内の文字を認識し、編集・検索できるテキストデータに変換する技術のことです。
スキャンPDFは一見すると通常の文書に見えますが、実際には文字が画像として保存されています。そのため、直接編集や検索はできません。
OCRを使用することで、文字・数字・表の構造を読み取り、WordやExcelで編集できる状態に変換できます。
たとえば、次のようなファイルは、そのままでは文字編集ができません。
- 画像として保存されたPDF
- スキャンした書類
- NotebookLMから書き出した「画像型PDFスライド」
こうしたファイルにOCRを実行すると、
文字情報が自動で抽出され、コピー・編集・検索が可能なPDFになります。
Part2. スキャンPDFをエクセルに変換するメリット
データを「計算・集計」できるようになる
スキャンPDFのままでは数値計算や並び替えができませんが、Excelに変換すれば、関数やフィルターを使った集計・分析が可能になります。
修正・再利用が簡単
Excel形式なら、数値修正や項目追加もスムーズです。定期的に更新する資料や、社内共有用のデータ管理にも向いています。
業務効率が大幅に向上
OCRで自動変換すれば、手入力に比べて作業時間とミスを大きく減らせます。
Part3. OCRでスキャンしたPDFをExcelに変換する方法
方法1:PDNob PDF編集ソフトを使う(おすすめ)
日本語の認識精度や、表の行・列構造をできるだけ崩さずにExcelへ変換したい場合は、OCR機能を搭載した PDNob PDF編集ソフトを使う方法が効率的です。
スキャンPDFをそのまま読み込み、OCR処理後にExcel(.xlsx)形式として出力できるため、手作業での修正を最小限に抑えられます。
変換手順
ステップ1.PDNobを起動して、スキャンPDFを読み込む
公式サイトからPDNobをインストールし、ソフトを起動します。
画面の「PDFを開く」をクリックし、エクセルに変換したいスキャンPDFファイルを選択します。
OCRソフトPDNobを無料ダウンロード:https://bit.ly/4tuvz7c
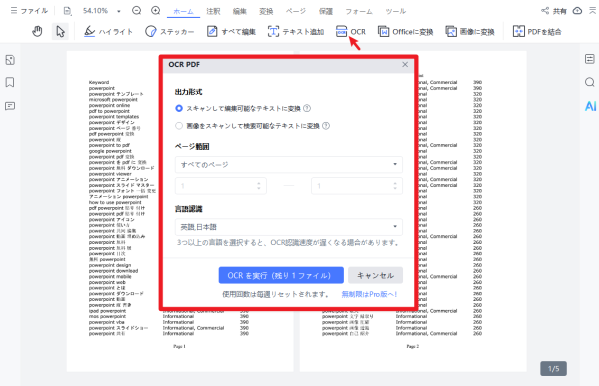
ステップ2.OCR機能を選択する
上部メニューから「OCR」をクリックします。
OCR設定画面が表示されるので、認識言語を「日本語」 に設定します。必要に応じて、処理するページ範囲も指定できます。
「OCRを実行」をクリックすると、スキャン画像内の文字や数値、表構造を解析し、編集可能なデータへ変換します。
上部メニューから「OCR」をクリックします。
OCR設定画面が表示されるので、認識言語を「日本語」 に設定します。必要に応じて、処理するページ範囲も指定できます。
「OCRを実行」をクリックすると、スキャン画像内の文字や数値、表構造を解析し、編集可能なデータへ変換します。
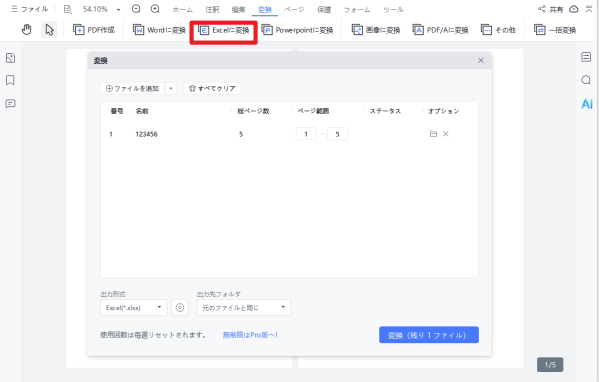
ステップ3.Excel形式でエクスポートする
OCR処理完了後、「変換」→「Excelに変換」を選択します。
保存先を指定すると、行・列を保持したExcelファイルが生成されます。
OCR処理完了後、「変換」→「Excelに変換」を選択します。
保存先を指定すると、行・列を保持したExcelファイルが生成されます。
ステップ4.Excelファイルを確認・微調整する
変換後のExcelを開き、数値や列のズレがないかを確認します。必要に応じてExcel上で簡単に修正できます。
変換後のExcelを開き、数値や列のズレがないかを確認します。必要に応じてExcel上で簡単に修正できます。
特徴・ポイント
日本語対応の高精度OCR
印刷された日本語文字や数字を正確に認識し、文字化けや誤認識を抑えられます。
表構造を保ったExcel変換
行・列・罫線をできるだけ維持したままExcelに変換でき、集計や計算にすぐ使えます。
ローカル処理で安心
ファイルを外部サーバーにアップロードせず、PC上で処理できるため、業務資料や機密データの取り扱いにも向いています。
方法2:GoogleドライブのOCR機能を使う(無料)
GoogleドライブにはOCR機能が標準搭載されており、追加ソフトをインストールせずにスキャンPDFをテキスト化できます。
簡単な資料や、一時的に内容を確認・再利用したい場合に向いている方法です。
変換手順
ステップ1.Googleドライブにアクセスし、「新規」→「ファイルのアップロード」からスキャンPDFをアップロードします。
ステップ2.アップロードしたPDFを右クリックし、「アプリで開く」→「Googleドキュメント」を選択します。
ステップ3.PDFがGoogleドキュメントとして開かれ、画像内の文字が自動的にOCR処理されます。
テキストは編集可能な状態になりますが、表はテキスト化されるだけで、セル構造は保持されません。
ステップ4.OCR後の内容をコピーし、Googleスプレッドシートに貼り付けます。列や行を手動で調整し、表形式に整えます。
ステップ5.Googleスプレッドシートの「ファイル」→「ダウンロード」から、「Microsoft Excel(.xlsx)」を選択して保存します。
注意点
表レイアウトはほぼ保持されない
行・列・罫線は崩れるため、Excel上での再構成が前提になります。
数値や改行のズレが発生しやすい
請求書や一覧表など、表中心のPDFには不向きです。
日本語精度はPDF品質に左右される
画質が低いスキャンPDFでは誤認識が増える傾向があります。
方法3:オンラインOCRツールを使う(インストール不要)
Online OCR などのWebサービスを利用すれば、ブラウザ上でスキャンPDFをExcel形式に変換できます。
ソフトを入れられない環境や、単発作業に向いている方法です。
基本的な使い方
ステップ1.OCR対応のオンラインツールにアクセス
ステップ2.スキャンPDFをアップロード
ステップ3.出力形式で「Excel(.xlsx)」を選択
ステップ4.OCR処理を実行し、変換後ファイルをダウンロード
ステップ5.操作自体はシンプルで、数クリックで変換が完了します。
特徴
インストール不要で手軽
ブラウザがあればすぐに使えます。
軽量PDF向け
ページ数が少なく、表構造が単純なPDFに向いています。
注意点
ファイルサイズ・ページ数に制限がある
無料版では複数ページや大容量PDFに対応できない場合があります。
日本語OCR・表認識の精度は低め
行や列がずれやすく、数値の誤認識も起こりやすいです。
セキュリティ面のリスク
PDFを外部サーバーにアップロードするため、業務資料や個人情報を含むファイルには注意が必要です。
Part4. スキャンPDFをエクセルに変換する際の注意点
画質が精度を左右する
解像度が低いPDFでは、文字や列のズレが発生しやすくなります。可能であれば300dpi以上でスキャンするのが理想です。
日本語OCRの設定を確認する
言語設定が英語のままだと、日本語は正しく認識されません。OCR実行前に必ず「日本語」を選択してください。
手書き文字は修正前提で
手書き文字は誤認識が起こりやすいため、変換後の確認・修正が必要です。
オンラインOCRのセキュリティ
業務資料や個人情報を含むPDFは、ローカルで処理できるOCRソフトの方が安全です。
まとめ
OCRを使えば、スキャンしたPDFでもExcel形式に変換し、数値や表データを自由に編集・活用できます。
無料ツールでも変換は可能ですが、日本語精度や表構造の保持には限界があります。
正確さと作業効率を重視するなら、日本語対応OCRとExcel出力に対応したツールを選ぶことが重要です。
PDNobを使えば、スキャンPDFでも行・列を保ったまま、実務で使えるExcelデータへスムーズに変換できます。
まずは無料版で精度を確認し、用途に合うか試してみるとよいでしょう。
製品情報・公式リンク
製品名:Tenorshare PDNob
公式サイト:https://bit.ly/4tuvz7c
公式ブログ:https://note.com/phonetips
日本語対応の高精度OCR
印刷された日本語文字や数字を正確に認識し、文字化けや誤認識を抑えられます。
表構造を保ったExcel変換
行・列・罫線をできるだけ維持したままExcelに変換でき、集計や計算にすぐ使えます。
ローカル処理で安心
ファイルを外部サーバーにアップロードせず、PC上で処理できるため、業務資料や機密データの取り扱いにも向いています。
方法2:GoogleドライブのOCR機能を使う(無料)
GoogleドライブにはOCR機能が標準搭載されており、追加ソフトをインストールせずにスキャンPDFをテキスト化できます。
簡単な資料や、一時的に内容を確認・再利用したい場合に向いている方法です。
変換手順
ステップ1.Googleドライブにアクセスし、「新規」→「ファイルのアップロード」からスキャンPDFをアップロードします。
ステップ2.アップロードしたPDFを右クリックし、「アプリで開く」→「Googleドキュメント」を選択します。
ステップ3.PDFがGoogleドキュメントとして開かれ、画像内の文字が自動的にOCR処理されます。
テキストは編集可能な状態になりますが、表はテキスト化されるだけで、セル構造は保持されません。
ステップ4.OCR後の内容をコピーし、Googleスプレッドシートに貼り付けます。列や行を手動で調整し、表形式に整えます。
ステップ5.Googleスプレッドシートの「ファイル」→「ダウンロード」から、「Microsoft Excel(.xlsx)」を選択して保存します。
注意点
表レイアウトはほぼ保持されない
行・列・罫線は崩れるため、Excel上での再構成が前提になります。
数値や改行のズレが発生しやすい
請求書や一覧表など、表中心のPDFには不向きです。
日本語精度はPDF品質に左右される
画質が低いスキャンPDFでは誤認識が増える傾向があります。
方法3:オンラインOCRツールを使う(インストール不要)
Online OCR などのWebサービスを利用すれば、ブラウザ上でスキャンPDFをExcel形式に変換できます。
ソフトを入れられない環境や、単発作業に向いている方法です。
基本的な使い方
ステップ1.OCR対応のオンラインツールにアクセス
ステップ2.スキャンPDFをアップロード
ステップ3.出力形式で「Excel(.xlsx)」を選択
ステップ4.OCR処理を実行し、変換後ファイルをダウンロード
ステップ5.操作自体はシンプルで、数クリックで変換が完了します。
特徴
インストール不要で手軽
ブラウザがあればすぐに使えます。
軽量PDF向け
ページ数が少なく、表構造が単純なPDFに向いています。
注意点
ファイルサイズ・ページ数に制限がある
無料版では複数ページや大容量PDFに対応できない場合があります。
日本語OCR・表認識の精度は低め
行や列がずれやすく、数値の誤認識も起こりやすいです。
セキュリティ面のリスク
PDFを外部サーバーにアップロードするため、業務資料や個人情報を含むファイルには注意が必要です。
Part4. スキャンPDFをエクセルに変換する際の注意点
画質が精度を左右する
解像度が低いPDFでは、文字や列のズレが発生しやすくなります。可能であれば300dpi以上でスキャンするのが理想です。
日本語OCRの設定を確認する
言語設定が英語のままだと、日本語は正しく認識されません。OCR実行前に必ず「日本語」を選択してください。
手書き文字は修正前提で
手書き文字は誤認識が起こりやすいため、変換後の確認・修正が必要です。
オンラインOCRのセキュリティ
業務資料や個人情報を含むPDFは、ローカルで処理できるOCRソフトの方が安全です。
まとめ
OCRを使えば、スキャンしたPDFでもExcel形式に変換し、数値や表データを自由に編集・活用できます。
無料ツールでも変換は可能ですが、日本語精度や表構造の保持には限界があります。
正確さと作業効率を重視するなら、日本語対応OCRとExcel出力に対応したツールを選ぶことが重要です。
PDNobを使えば、スキャンPDFでも行・列を保ったまま、実務で使えるExcelデータへスムーズに変換できます。
まずは無料版で精度を確認し、用途に合うか試してみるとよいでしょう。
製品情報・公式リンク
製品名:Tenorshare PDNob
公式サイト:https://bit.ly/4tuvz7c
公式ブログ:https://note.com/phonetips


