画像PDFからテキストを抽出:https://bit.ly/4almxjW
PDFから文字を取り出したいのに、「コピーできない」「文字が選択できない」と困ったことはありませんか?
特に、スキャンされたPDFや画像PDFでは、通常のコピー操作ではテキスト抽出ができず、OCR(光学文字認識)を使ったPDF文字起こしが必要になります。
この記事では、
PDFテキスト抽出の仕組み
PDFをテキストに変換できない原因と対処法
無料で使えるOCRツール
日本語対応で高精度なPDF文字起こし方法
を初心者にも分かりやすく解説します。
1.PDFテキスト抽出の仕組み
PDFから文字を抽出する方法は、PDFの種類によって異なります。
① テキストPDF
WordやGoogleドキュメントなどから作成されたPDFは、文字情報を内部に保持しています。
この場合、PDFソフトが文字データを直接読み取るため、高精度かつ高速にテキスト抽出が可能です。
② 画像PDF(スキャンPDF)
紙書類をスキャンしたPDFは、文字が画像として保存されています。
そのため、OCR(光学文字認識)を使って画像から文字を認識し、テキスト化します。
抽出精度は、画像の解像度や文字の鮮明さに左右されます。
2. PDF文字起こしの種類と簡単なやり方
PDFの文字起こし方法は、PDFが「テキスト型」か「画像型」かによって大きく異なります。
まずは自分のPDFがどちらに当てはまるかを確認しましょう。
1. テキスト抽出可能なPDFの場合(無料)
Word・Googleドキュメント・AIツールなどから作成されたPDFは、文字情報を内部に保持しているテキスト型PDFです。
このタイプのPDFであれば、特別なソフトは不要で、無料で文字起こしが可能です。
方法
Step1.Google Chrome または Microsoft Edge でPDFを開く
Step2.抽出したい文字をドラッグして選択
Step3.右クリック、または Ctrl + C(Macは command + C)でコピー
Step4.コピーしたテキストは、そのままメモ帳やWord、Googleドキュメントに貼り付けられます。
メリット
無料で使える
操作が非常に簡単
OCR不要で高精度
注意点
段組みや表はレイアウトが崩れやすい
フォントや文字コードの影響で文字化けすることがある
コピー制限が設定されているPDFでは使用できない
2. テキストを抽出できないPDF(画像PDF)の場合
紙書類をスキャンしたPDFや、写真から作成されたPDFは、文字が画像として保存されているため、選択やコピーができません。
この場合は、OCR(光学文字認識)を使ったPDF文字起こしが必要です。
無料OCRツールでも対応は可能ですが、
● 日本語認識精度が低い
● 表やレイアウトが崩れやすい
● ファイルサイズや枚数制限がある
といった制約があります。
そこでおすすめなのが Tenorshare PDNob です。
Tenorshare PDNobの特徴
● 日本語に対応した高精度OCR
● ぼやけたスキャンPDFや古い資料でも認識しやすい
● コピー制限付きPDFでもスクリーンOCRで文字抽出可能
● オフライン環境で使用でき、情報漏えいの心配が少ない
操作手順(OCRによるPDF文字起こし)
Step1.公式サイトから Tenorshare PDNob をダウンロードし、Windows または Mac にインストールします。
公式サイトよりPDNobを無料・安全にダウンロード:https://bit.ly/4almxjW
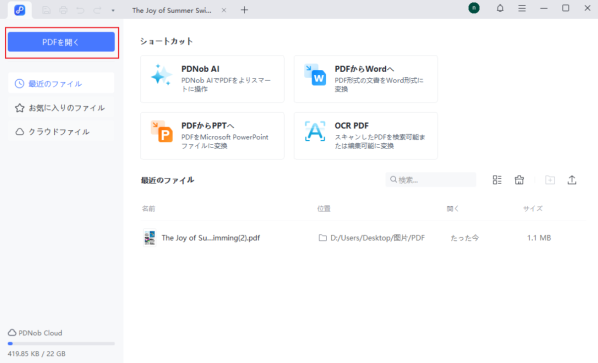
ソフトを起動し、トップ画面の「PDFを開く」をクリックして、文字起こししたいPDFファイルを追加します。
PDFから文字を取り出したいのに、「コピーできない」「文字が選択できない」と困ったことはありませんか?
特に、スキャンされたPDFや画像PDFでは、通常のコピー操作ではテキスト抽出ができず、OCR(光学文字認識)を使ったPDF文字起こしが必要になります。
この記事では、
PDFテキスト抽出の仕組み
PDFをテキストに変換できない原因と対処法
無料で使えるOCRツール
日本語対応で高精度なPDF文字起こし方法
を初心者にも分かりやすく解説します。
1.PDFテキスト抽出の仕組み
PDFから文字を抽出する方法は、PDFの種類によって異なります。
① テキストPDF
WordやGoogleドキュメントなどから作成されたPDFは、文字情報を内部に保持しています。
この場合、PDFソフトが文字データを直接読み取るため、高精度かつ高速にテキスト抽出が可能です。
② 画像PDF(スキャンPDF)
紙書類をスキャンしたPDFは、文字が画像として保存されています。
そのため、OCR(光学文字認識)を使って画像から文字を認識し、テキスト化します。
抽出精度は、画像の解像度や文字の鮮明さに左右されます。
2. PDF文字起こしの種類と簡単なやり方
PDFの文字起こし方法は、PDFが「テキスト型」か「画像型」かによって大きく異なります。
まずは自分のPDFがどちらに当てはまるかを確認しましょう。
1. テキスト抽出可能なPDFの場合(無料)
Word・Googleドキュメント・AIツールなどから作成されたPDFは、文字情報を内部に保持しているテキスト型PDFです。
このタイプのPDFであれば、特別なソフトは不要で、無料で文字起こしが可能です。
方法
Step1.Google Chrome または Microsoft Edge でPDFを開く
Step2.抽出したい文字をドラッグして選択
Step3.右クリック、または Ctrl + C(Macは command + C)でコピー
Step4.コピーしたテキストは、そのままメモ帳やWord、Googleドキュメントに貼り付けられます。
メリット
無料で使える
操作が非常に簡単
OCR不要で高精度
注意点
段組みや表はレイアウトが崩れやすい
フォントや文字コードの影響で文字化けすることがある
コピー制限が設定されているPDFでは使用できない
2. テキストを抽出できないPDF(画像PDF)の場合
紙書類をスキャンしたPDFや、写真から作成されたPDFは、文字が画像として保存されているため、選択やコピーができません。
この場合は、OCR(光学文字認識)を使ったPDF文字起こしが必要です。
無料OCRツールでも対応は可能ですが、
● 日本語認識精度が低い
● 表やレイアウトが崩れやすい
● ファイルサイズや枚数制限がある
といった制約があります。
そこでおすすめなのが Tenorshare PDNob です。
Tenorshare PDNobの特徴
● 日本語に対応した高精度OCR
● ぼやけたスキャンPDFや古い資料でも認識しやすい
● コピー制限付きPDFでもスクリーンOCRで文字抽出可能
● オフライン環境で使用でき、情報漏えいの心配が少ない
操作手順(OCRによるPDF文字起こし)
Step1.公式サイトから Tenorshare PDNob をダウンロードし、Windows または Mac にインストールします。
公式サイトよりPDNobを無料・安全にダウンロード:https://bit.ly/4almxjW
ソフトを起動し、トップ画面の「PDFを開く」をクリックして、文字起こししたいPDFファイルを追加します。
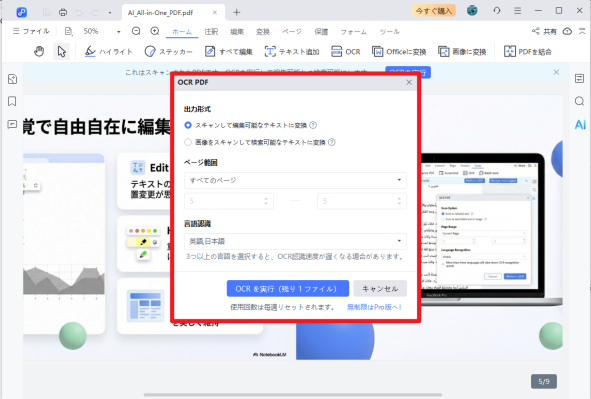
Step2.PDFが表示されたら、上部メニューにある「OCR」ボタンをクリックします。
OCR設定画面で、認識言語(日本語など)や文字起こしを行うページ範囲を指定します。
設定内容を確認したうえで、「OCRを実行」をクリックして処理を開始します。
OCR設定画面で、認識言語(日本語など)や文字起こしを行うページ範囲を指定します。
設定内容を確認したうえで、「OCRを実行」をクリックして処理を開始します。
Step3.OCR処理が完了したら、テキスト化されたPDFを任意の形式で保存します。
初心者でも、数クリックの簡単な操作でPDFの文字起こしを完了できます。
Tenorshare PDNobがおすすめな理由
● 表や画像を含むPDFでも、レイアウトが崩れにくい
● OCR後のテキストを直接編集できる
● 16言語以上に対応しており、多言語PDFにも対応可能
● インターネット不要で使用でき、業務データの管理も安心
● NotebookLMなどのAIで作成されたPDFスライドも高精度で認識でき、編集可能なPPT形式へ変換しやすい
初心者でも、数クリックの簡単な操作でPDFの文字起こしを完了できます。
Tenorshare PDNobがおすすめな理由
● 表や画像を含むPDFでも、レイアウトが崩れにくい
● OCR後のテキストを直接編集できる
● 16言語以上に対応しており、多言語PDFにも対応可能
● インターネット不要で使用でき、業務データの管理も安心
● NotebookLMなどのAIで作成されたPDFスライドも高精度で認識でき、編集可能なPPT形式へ変換しやすい
Part3. OCRでPDFをテキスト化できるおすすめツール
OCRでPDFをテキスト化する方法には、オンライン型とソフト型があります。
ここでは、手軽に使えるオンラインOCRツールを中心に紹介します。
①. Smallpdf OCR/iLovePDF OCR
操作が非常にシンプルで、OCR初心者でも迷わず使えるオンラインツールです。
特徴
PDFをアップロードするだけで自動的にOCR処理が行われる
Word、TXT、Excel形式への変換に対応
インターフェースが直感的で操作しやすい
向いている人
たまにPDFの文字起こしをしたい人
操作の簡単さを重視する人
注意点
OCR機能は有料プラン限定
日本語の認識言語設定を誤ると文字化けしやすい
機密文書には不向き(クラウド処理)
②.Googleドキュメント(無料OCR)
Googleアカウントがあれば誰でも利用できる、完全無料のOCR方法です。
PDFや画像ファイルをGoogleドキュメントで開くだけで、自動的に文字起こしが行われます。
特徴
PDFや画像ファイルをアップロードするだけでOCR処理が実行される
OCR後のテキストをそのまま編集・共有・翻訳できる
ソフトのインストール不要で、ブラウザ上ですぐに利用可能
向いている人
費用をかけずにOCRを試してみたい人
短い文書や簡易的な文字起こしで十分な人
Googleドキュメントを日常的に使っている人
注意点
レイアウトの再現性は低く、段組みや表は大きく崩れやすい
縦書き文書や日本語の特殊文字、記号の認識が苦手
画像の解像度や文字の鮮明さによって認識精度が大きく変わる
ページ数の多いPDFでは処理に時間がかかることがある
まとめ
PDFからテキストを抽出する方法は、PDFの種類によって異なります。
テキスト型PDF:ブラウザで開いて、そのまま無料でコピー可能
画像PDF・スキャンPDF:OCRによる文字起こしが必須
無料OCRツールでも対応は可能ですが、日本語の認識精度・レイアウト保持・制限付きPDFへの対応を重視する場合は、
Tenorshare PDNob のような専用OCRソフトがおすすめです。
「PDFから文字を抽出できない」「文字化けやレイアウト崩れに困っている」という方は、まずは PDNobの無料体験版 で、実際のOCR精度を確認してみてください。PDF作業の効率が大きく向上するはずです。
製品情報・公式リンク
製品名:Tenorshare PDNob
公式サイト:https://bit.ly/4almxjW
公式ブログ:https://note.com/phonetips


